Free Data Cleaning for Google Sheets
Flookup is a Google Sheets add-on that uses fuzzy matching to clean, deduplicate and standardise your data in mere minutes, not hours.
See Flookup in Action
Featured Articles from the Blog
Read practical guides on data cleaning, fuzzy matching and automation in Google Sheets.
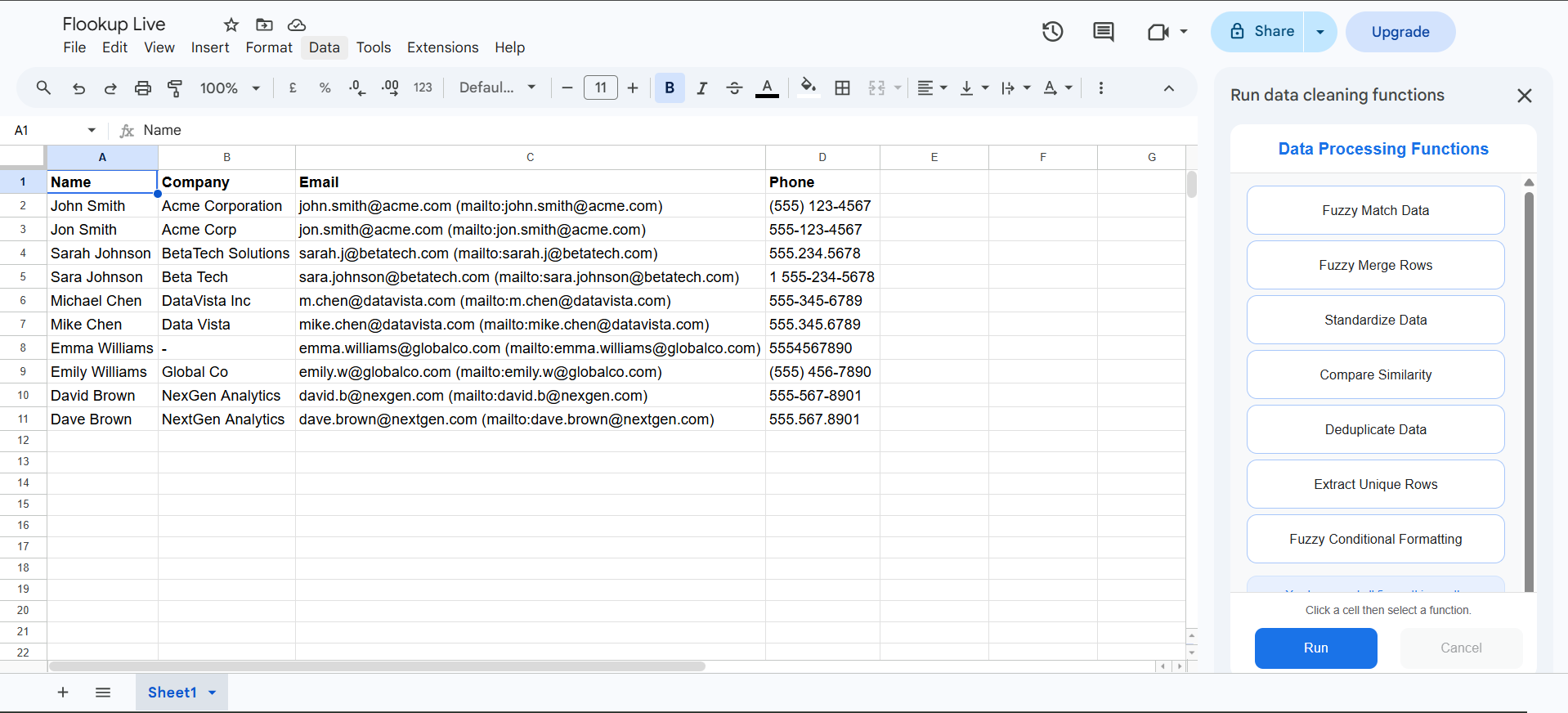
Advanced Data Cleaning Operations
Select the workflow that best aligns with your source data to rapidly clean records using our sophisticated fuzzy matching and standardisation tools.
Fuzzy Matching
Find matching records across datasets even with typos, abbreviations and inconsistent formatting. Reconcile data automatically using configurable similarity thresholds.
Deduplication
Remove near-duplicate rows that exact matching misses. Catch phonetic and typographical variations with configurable sensitivity.
Text Standardisation
Strip punctuation, diacritics and stop words. Extract URL components. Normalise messy text into clean consistent formats across your sheets.
Learn from Examples
Teach transformations by showing dirty-clean example pairs. The system learns the pattern automatically. No formulas or scripting required.
Scheduled Automation
Set and forget your data cleaning. Schedule deduplication and standardisation to run every 15 minutes, hourly or daily. Handles large datasets with auto-chaining across execution windows.
Sheets AI Assistant
Describe your data problem in plain language and get accurate formula suggestions, step-by-step guidance and data cleaning strategies tailored to your sheets.
Join Thousands of Satisfied Users
"Flookup has been a game-changer. The fuzzy matching function saves me hours of manual work cleansing data across multiple files. So much faster and more accurate than anything else I have tried!"
"This tool fits perfectly into our Google Sheets workflows. The fuzzy matching is easy to use and the customer support team is incredibly helpful. Highly recommended!"
"Flookup is fantastic for fuzzy matching and address scraping. It has saved us weeks of work and improved our data quality significantly. A must-have add-on!"
"Fantastic customer service and a huge time-saver for data cleansing. The ability to handle thousands of rows efficiently has transformed how we manage our spreadsheet data."